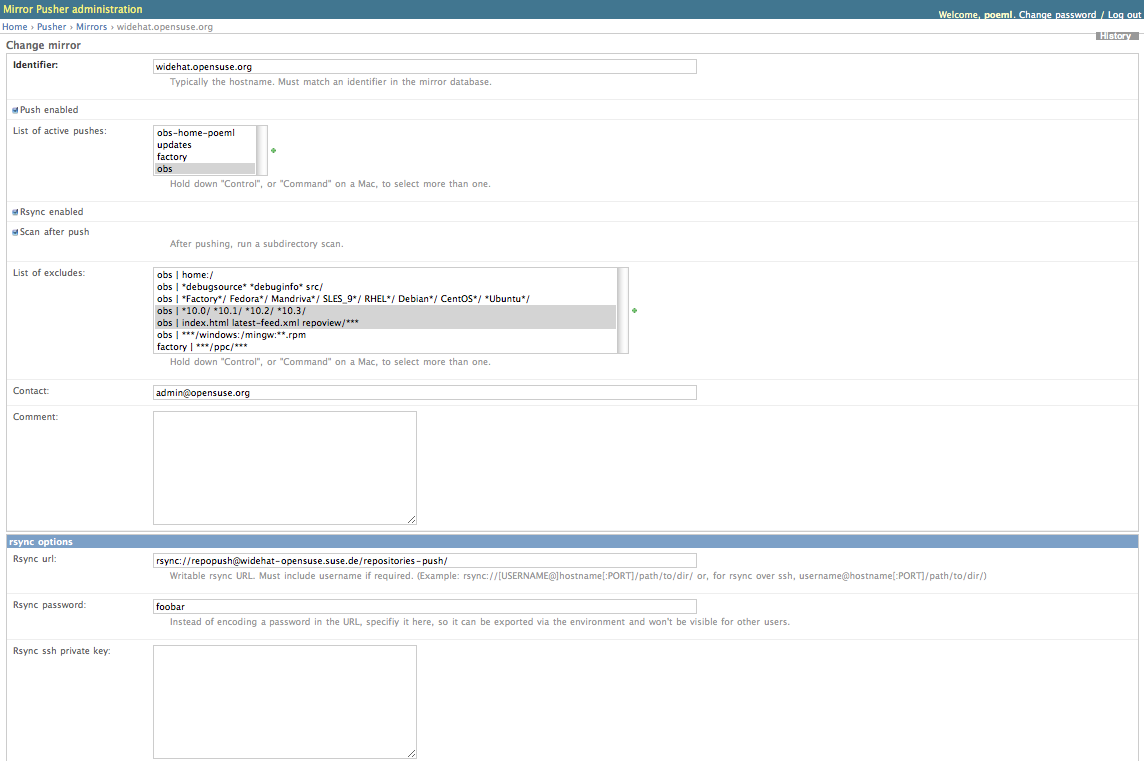
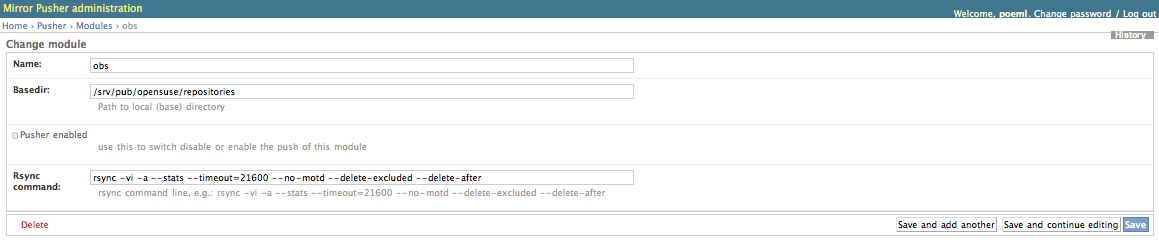
On Fri, Sep 25, 2009 at 6:14 AM, Peter Pöml <poeml_at_cmdline.net> wrote: > Hi! > > On 25.09.2009, at 02:40, David Farning wrote: > >> Peter ask me to continue a private thread on this mailing list. Also >> CCing Matthew Zeier from mozilla infrastructure. I was looking for >> Mozilla's solution and he pointed me in the direction of mirrorbrain. >> >> On Thu, Sep 24, 2009 at 5:25 PM, Peter Pöml <poeml_at_cmdline.net> wrote: >>> >>> Hi David! >>> >>> thank you for writing. Interesting to learn about Sugar. It sounds >>> exciting! >>> >>> Would you mind me resending my reply with the MirrorBrain mailing list >>> Cc'ed, and continue discussion there? I think it would be great material >>> for >>> the list and could provide insight to others. It's also great to see some >>> activity there :-) (If not, no problem at all.) >> >> done > > Thank you. (I actually had the other mailing list in mind, mirrorbrain@, but > it doesn't matter much, the same people are subscribed there - the discuss > list was meant more for discussion of mirror issues regardless of > MirrorBrain; I should have said that. But I guess it doesn't matter that > much!) > >>> On 24.09.2009, at 22:33, David Farning wrote: >>>> >>>> I am looking at using mirrorbrain as the CDN for wki.sugarlabs.org . >>>> We are still pretty small we generally have 200G per day but peak at >>>> 32000G per day during releases. >>> >>> That's not nothing ;) I'd say it is an amount where a carefully set up >>> infrastructure with mirrors makes sense. Also, it sounds like there would >>> be >>> a lot of users that one wants to keep happy, and who would benefit from >>> every improvement. And from looking >> >> We are currently running our infrastructure from the FSF's colocation >> facility. So I include keeping our generous host happy pretty high on >> the list. > > > Yes, understandably. > > >>>> On normal day the majority of our traffic comes from >>>> activities.sugarlabs.org . a.sl.o is based off of mozilla's amo so >>>> anything we do here help them. >>> >>> I see, http://activities.sugarlabs.org/ is very similar as >>> https://addons.mozilla.org/, and it offers download links to lots of .xo >>> files, and redirects to >>> http://download.sugarlabs.org/sources/activities/ from where the files >>> are >>> downloaded. >>> For now, I only note the redirection to d.sl.o, and no further >>> redirection >>> from there. >>> >>> I also see other downloads, like >>> http://wiki.sugarlabs.org/go/Sugar_on_a_Stick which links to some >>> mirrors. >>> >>>> We have a small collection of mirrors that help us during releases. >>>> But, the user must manually chose between mirrors. Agggg. >>> >>> Okay, so from what I would guess at this stage is that d.sl.o could >>> redirect >>> to the mirrors, instead of delivering the .xo files all by itself; >>> correct? >>> That would be exactly where MirrorBrain is could step in. >> >> >> Yes, the two main pieces are the sugar on a stick images and the .xo >> files. > > > Okay. > > >>>> My questions are: >>>> 1. Is it worth it to use mirrorbrain at this stage? Particularly >>>> around releases. >>> >>> Yes, definitely, the only thing to keep in mind is that deploying it >>> costs >>> time, but I would think that it is worth the effort. If you have very few >>> mirrors, it can be the life-saver for the releases -- and if you >>> gradually >>> get more mirrors, it will improve the service quality for the end users >>> because they can usually be routed to a better mirror. >> >> Yes, this is particularly important because many of our large >> deployments are in remote regions. Something like 80% of our .xo >> traffic is from Uruguay. > > > I see. > > >>> The effort in deployment is mainly in building and installing the >>> software >>> and its different components. This is certainly doable and I'm happy to >>> help >>> with it. If you run, say, purely on a CentOS5 based shop with aged Apache >>> and complicated deployment procedures, it can be difficult, but d.sl.o >>> rather seems to run Apache/2.2.11 on Ubuntu, which means that Apache is >>> new >>> enough, and everything else will be available as well I guess. I would >>> actually like to build MirrorBrain packages on Ubuntu, and that might be >>> a >>> reason to do that maybe? >> >> Everything except the build farm is Ubuntu. Ubuntu packages would be >> nice. But I am willing to build from scratch. > > > Which Ubuntu version specifically? In the openSUSE build service, I can > build for 8.04, 8.10, and 9.04. It would also be interesting for me to > become a real Debian package maintainer, but using the openSUSE build > service might be the quicker route for now. I managed to build mod_asn for > Debian and Ubuntu already (see > http://download.opensuse.org/repositories/Apache:/MirrorBrain/xUbuntu_9.04/), > and I'm confident that I could do the same for mod_mirrorbrain and stuff > that you would need. Those package would be updated then from a single > source together with the various RPM packages that are built, which would be > of great convenience later. > > Most needed dependencies should already be available for a modern > Debian/Ubuntu system. One thing that may be needed to be double-checked is > mod_geoip. It seems that this module is very outdated - > http://packages.qa.debian.org/liba/libapache2-mod-geoip.html has an 1.1.x > version, and there is a newer package waiting in > http://mentors.debian.net/debian/pool/main/l/libapache2-mod-geoip/ but even > that is already 1.5 years old. > > >>>> 2. How will mirror brain interact will a.sl.o(AMO)? Will new >>>> activites just be served from that primary node until mirrorbrain runs >>>> a scan to verify the the new activite has been rsynced to a mirror >>>> node. >>> >>> MirrorBrain needs the file tree locally and can work off it as a normal >>> Apache. If it doesn't know a mirror for a file, Apache will just deliver >>> it >>> as normal; if a mirror is known, Apache will redirect to it. Therefore, >>> publishing new files is just a matter of putting them into the file tree. >>> Later, mirrors will catch up, and as soon as they are scanned, Apache >>> will >>> know about the presence on the mirrors and redirect to them. >> >> Ok great, so then we can modify the rsync so that only popular files >> are mirrored. a.sl.o keeps every version of an activity in the main >> tree for historical purposes. But there is no reason to keep copies >> on the mirrors. > > > Yes, this makes sense. > > >>> If large amounts of content are published at once, it can be useful (or >>> even >>> needed) to first publish them only for the mirrors, by putting them into >>> a >>> stage area that they can access, and later update Apache's file tree, >>> when >>> they are distributed enough. Another regime (useful if the file tree is >>> large and gets frequent, small updates) could be to push-sync files as >>> soon >>> they come in, and directly scan after each push. >> >> Ok, we can figure that out. It would be cool if a.sl.o could trigger >> the push when ever a new activity is added. > > > I started working on some kind of framework for this purpose, because the > same need arose at openSUSE in the past, and there it was implemented with > some simple (and hard to maintain) shell scripts. I am thinking of a Django > web app to configure the pushes for mirrors, and a little job queue that > runs the push syncs, and which is triggered by e.g. XML-RPC or REST > interface, or by inotifies directly from the filesystem. > > The web frontend part I have almost implemented, and I've put some > screenshots here to make the idea a little visible: > > http://www.poeml.de/~poeml/MirrorSync/mirrors.png > http://www.poeml.de/~poeml/MirrorSync/modules.png > http://www.poeml.de/~poeml/MirrorSync/excludes.png > > This is not of much practical use yet, but it might be an interesting path > to go in the future. It's definitely something that other people/projects > also have a need for, so a reusable and simple framework could be useful I > thought. > > (The code is in a private SVN repository so far, just because I was > experimenting with live data and needed to have passwords in the database) > > >>> Maybe there is even an existing release infrastructure that one could >>> integrate with. >> >> We are not that fancy yet. >> >>>> 3. How does mirrorbrain work with mysql? Do the admin framework and >>>> tool set work with mysql yet? >>> >>> At the beginning of this year, I abandoned MySQL support in all the >>> tools, >>> but the core (the mod_mirrorbrain Apache module) will work. The tools to >>> maintain the mirror database won't work, and while this could probably be >>> fixed, I can say that when the list of mirrors is not long, and one is >>> proficient in the mysql commandline, it is certainly possible to maintain >>> the mirror data manually with the mysql client. I did so for a long time >>> in >>> fact, before I finally started to write some tools. >>> >>> I would recommend to use PostgreSQL because that will result in a setup >>> that >>> is clean and as documented, and also the database will be self-contained >>> and >>> low-maintenance enough that it would matter much to anyone which database >>> is >>> used underneath. >>> >>> However, mod_mirrorbrain will happily use MySQL as file database. I am >>> *quite* sure that the scanner script also still works with MySQL, but I >>> can't promise, as I haven't tested it since I did the switch to >>> PostgreSQL. >>> >>> I decided to switch to PostgreSQL because Apache's DBD framework cannot >>> use >>> two different databases in one vhost yet, and I needed a special datatype >>> in >>> PostgreSQL to implement mod_asn (which you won't need with only few >>> mirrors; >>> don't bother to install it). I was aware that it might put off some >>> people >>> that are more familiar with MySQL, but I can speak very positively about >>> PostgreSQL, it is a great piece of software and it was a pleasurable >>> experience to me to get acquainted with it. I am happy to help with that; >>> it's not difficult, just a little different. >> >> Using postgresSQL is not a blocker. So we can worry about that later. >> >>> It would of course be an option to re-implement MySQL support and >>> PostgreSQL >>> at the same time, but my time has been to scarce so far to even consider >>> this, as there are other things that would seem more important, as e.g. >>> the >>> lack of a web interface, that I would like to tackle. >>> >>> >>> Does this help further? >> >> So, I guess my next steps are: >> 1. set up a opensuse VM and install mirrorbrain to see how it is >> suppose to work. > > > I once created a VirtualBox image based on openSUSE 11.1, which may be the > quickest way to have a look: > http://mirrorbrain.org/news/mirrorbrain-eval-virtualbox-appliance/ > It contains a complete install and one or two (Firefox) mirrors set up, and > it should allow you to immediately play with Apache as well as with the "mb" > admin tool (see http://mirrorbrain.org/docs/mirrors/). > > You could adjust the path to the file tree in the Apache configuration (see > /etc/apache2/vhosts.d/*.conf), rsync a copy of the file tree into the image, > add your mirrors to the database, scan them and you should have a working > redirector then. > >> 2. Set up a ubuntu VM matching the sugar labs infrastructure and >> install mirrorbrain. >> >> I'll try to do that this weekend. I am sure I will have questions > > > As happy as I would be to directly assist you with it, I'll be away for the > weekend unfortunately (and leave now). But I'm back on Monday! > Thanks Peter As promised, I created a recipe to to set up mirrorbrain for Sugar Labs at http://wiki.sugarlabs.org/go/Infrastructure_Team/Content_Delivery_Network . I have asked our Bernie, the Sugar Labs sysadmin, to set up a ubuntu 9.04 vm so I can do more testing this week. I have three vms set up as mirrors and one vm set up as the mirror brain on my desktop. I am downloading to thee laptops on a wired network. The current bottle neck is the laptop harddrives. Every thing looks good so far. Thanks for all your help. david _______________________________________________ discuss mailing list Archive: http://mirrorbrain.org/archive/discuss/ Note: To remove yourself from this mailing list, send a mail with the content unsubscribe to the address discuss-request_at_mirrorbrain.orgReceived on Mon Sep 28 2009 - 00:08:17 GMT
This archive was generated by hypermail 2.2.0 : Fri Dec 11 2009 - 22:12:59 GMT
{kind=link}
{kind=link}
{kind=link}